Сборка веб-страницы из частей. Включение кода HTML одного файла в другой
Когда создается сайт, состоящий из многих веб-страниц, то обычно каждая сверстана на том же макете, что другие. У всех одинаковый заголовок сайта (логотип, название веб-ресурса), основная навигация, подвал сайта и, если есть, другие блоки. Веб-документы часто отличаются между собой только содержащимися в них статьями.
Поэтому существует проблема выноса одинаковых частей страниц сайта в отдельные файлы с последующим их подключением (включением, импортом) в готовые (предназначенные для просмотра в браузере пользователями) веб-страницы.
Например, мы создаем отдельный файл, в котором на языке HTML описываем ссылки меню. Далее в коде каждой веб-страницы пишем одну команду, которая вставляет содержимое меню. Позже, когда потребуется внести изменения в навигацию сайта, надо будет исправить всего один файл. Не придется редактировать все страницы сайта.
Не смотря на очевидную необходимость, данный вопрос не имеет решения исключительно средствами языка HTML. То есть нет команды HTML, которая выполнила бы поставленную задачу целиком и полностью.
Однако проблема решается средствами многих других языков программирования, следовательно у нее нет однозначного решения. Каждый из способов накладывает свои особенности и некоторые сложности в обслуживании сайта. Поэтому если сайт состоит из небольшого количества страниц, то может быть проще оставить все как есть. Кроме того есть программы и утилиты, позволяющие выполнять поиск по содержимому группы текстовых файлов (html-документы к таковым относятся) с последующей заменой контента.
В этом уроке мы рассмотрим два способа включения содержимого одного файла в другой: с помощью JavaScript и PHP. Первый способ удобен тем, что не требует установки веб-сервера на локальном компьютере. Второй – более профессиональный и общепринятый подход.
Пусть мы хотим вынести одинаковые на всех страницах сайта навигационные ссылки в отдельный файл.
Создадим файл menu.js и поместим туда ссылки, убрав их из файлов *.html.
Поскольку мы будем включать в веб-документы скрипт JS, то и содержимое menu.js должно быть написано не на языке HTML, а на JavaScript.
В JS есть метод write , который выводит на странице переданный в него текст. Поэтому содержимое файла menu.js может выглядеть так:
document.write('\ Водоросли\ Лишайники\ Моховидные\ ');
Или так, если использовать свойство innerHTML (этот способ может быть предпочтительным):
document.getElementById("sidebar").innerHTML = '\ Водоросли\ Лишайники\ Моховидные'
Обратный слэш используется для экранирования перехода на новую строку (для интерпретатора JS разрыв строки перестает существовать).
В файлах *.html в места, откуда мы убрали ссылки, добавляем наш скрипт:
nav id="sidebar"> script src="menu.js">/script> /nav>

В данном случае выгода от наших манипуляций не очевидна. Но представьте, что меню состоит из сотни ссылок. Убрав его в отдельный файл, вы уменьшите объем кода в основных страницах, что упростит их последующее редактирование.
Хотя это не имеет отношения к теме текущего урока, обратите внимание на скриншот выше, где пункт меню, который ссылается на открытую в браузере страницу, имеет иное оформление. Так пользователю сайта легче понять, на какой странице он находится. В данном случае фокус был реализован с помощью подобного скрипта в конце тела каждого html-документа:
script type="text/javascript"> document.querySelector( 'a[href="lichen.html"]' ).style.background="White"; script>
Скрипт можно сделать универсальным и вынести в отдельный файл, если определять текущую страницу путем извлечения имени файла из ее адреса (код будет сложнее).
Если мы посмотрим на исходный код веб-документа в браузере ( Ctrl + U ), то не увидим здесь ссылок.
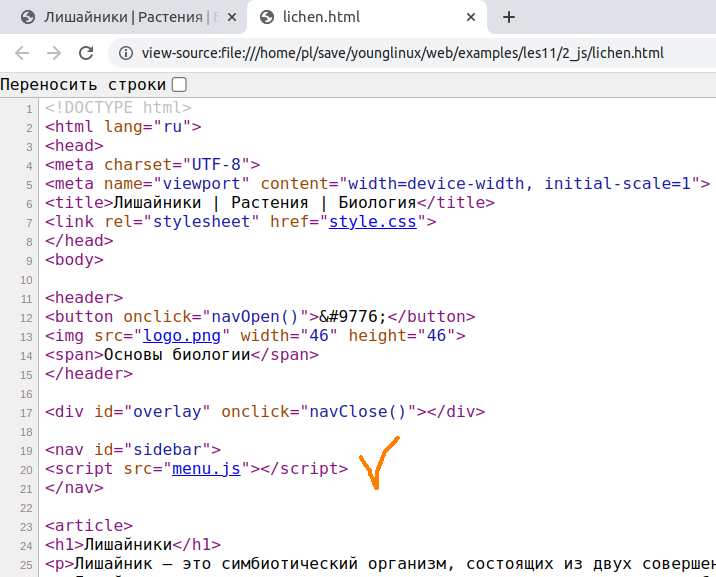
Интерпретатор браузера выполняет js-скрипт, на который указывает ссылка, но код страницы он не правит. Плохо ли это с точки зрения индексации контента поисковыми системами сказать трудно. Возможно, что их роботы не заходят в js-файлы и не анализируют их содержимое.
Другое дело, когда мы используем PHP или другой язык программирования. В этом случае скрипт выполняется на стороне сервера. По сети в браузер пользователя передается готовый документ, то есть без вставок кода на языке программирования. Вместо этого там находится результат выполнения этого кода.
К сожалению, чтобы увидеть как работают включения PHP в код HTML, нужен веб-сервер с интерпретатором PHP. Данное ПО можно установить на локальный компьютер, однако в данном курсе мы не будем этого делать. Для этого потребовался бы отдельный урок, в то время как острой необходимости в локальном сервере у нас нет.
Вместо этого следующий урок будет посвящен размещению сайта в сети Интернет. Подавляющее большинство виртуальных хостингов имеют уже настроенный веб-сервер, интерпретатор PHP и другое программное обеспечение, необходимое для работы и обслуживания сайта. Поэтому для того, чтобы увидеть как все работает, достаточно будет выгрузить файлы на хостинг.
Однако то, как с помощью PHP собрать веб-страницу из частей, рассмотрим в этом уроке.
Обычно веб-серверы по-умолчанию настроены так, что файлы с расширением *.php обрабатываются интерпретатором PHP, а файлы *.html – нет. Поэтому первое, что мы сделаем – поменяем расширения веб-страниц. Например, было: algae.html, lichen.html, moss.html. Стало: algae.php, lichen.php, moss.php.
Минусом такого подхода является то, что вы не сможете открывать страницы в браузере у себя на компьютере.
Также здесь отметим важный момент с точки зрения продвижения сайта. Адреса https://ваш-домен.зона/algae.html и https://ваш-домен.зона/algae.php разные. Если вы вдруг решите поменять расширения файлов у проиндексированного сайта, то поисковые системы решат, что старые страницы исчезли, появились какие-то новые. Конечно, можно настроить так называемые редиректы. Однако лучше продумывать адресацию на сайте заранее.
С другой стороны, редко когда увидишь, чтобы в адресной строке отображались расширения страниц. Обычно их скрывают. Например, следующие команды в файле .htaccess позволяют обращаться к страницам сайта без их расширения *.php:
RewriteEngine On RewriteCond % !-d RewriteCond %\.php -f RewriteRule ^(.*)$ $1.php
В таком случае веб-страница будет выглядеть как https://ваш-домен.зона/algae. Изменив имена файлов, необходимо изменить адреса в ссылках меню. Пусть они хранятся в файле menu.html. Так как это включаемый файл без кода на PHP, то и расширение можем оставить соответствующее содержимому.
a href="algae">Водоросли/a> a href="lichen">Лишайники/a> a href="moss">Моховидные/a>
В файлах веб-страниц php-включение будет выглядеть так:
nav id="sidebar"> "menu.html"; ?> /nav>
Команда языка PHP здесь include «menu.html» . Она приказывает вставить в документ содержимое указанного файла. Предваряющая ее последовательность символов в конце говорят, что этот код закончился.
Выгрузив все файлы сайта на хостинг и открыв веб-страницу через адресную строку, увидим результат выполнения команды include .
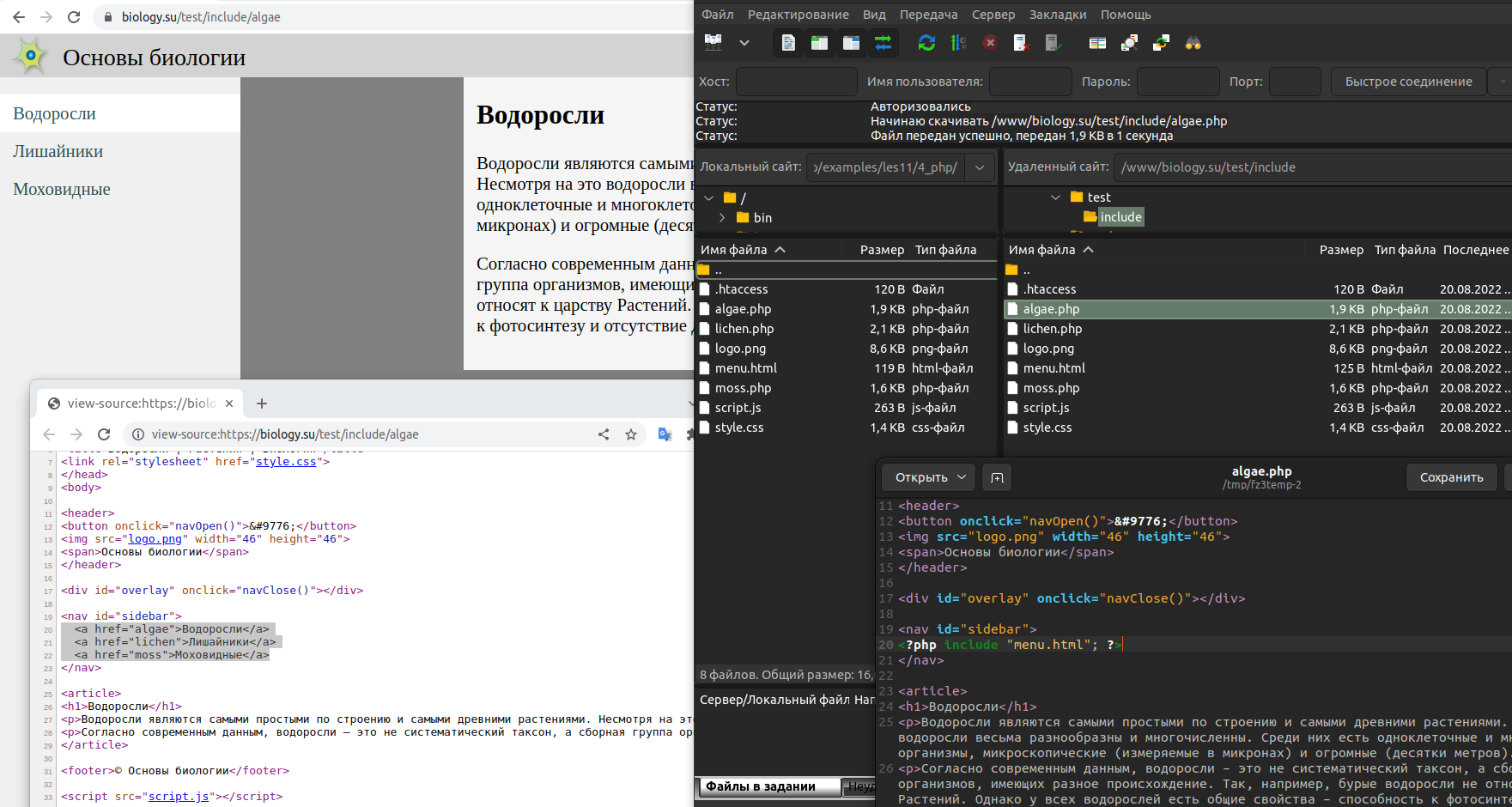
В нашем примере мы выделили в отдельный файл только меню сайта. Однако так делают в том числе для заголовка сайта, подвала и другого. Таким образом, веб-страница может содержать множество включений кода PHP в разных местах.
X Скрыть Наверх
Введение в веб-разработку и создание сайтов
PHP | Как вставить HTML код из разных файлов?
Обычно, стандартные страницы сайта в формате HTML требует постоянного заполнения одних и тех же элементов (тегов). Например, у нас есть интернет-магазин, в котором 30000 страниц товаров. На каждой такой странице есть одна и та же информация с кодами счётчиков поисковых систем, с кодами всплывающих окон чатов и мессенджеров, с кодами просьбы обратного звонка, с кодами разделов, с кодами верхнего и нижнего меню («шапки» и «подвала») и т.д..
Все эти коды (скрипты) заимствуют содержимое с других ресурсов, а значит их интеграция на ваш сайт должна быть максимально простой и адаптивной (в одну строку).
Нет смысла вручную создавать HTML документы и складывать их в папку с относительными путями ссылок внутри HTML-кода. А вдруг вы что-то захотите поменять в меню или в рекламном блоке. Вдруг поменяется код счётчика. Что тогда? Менять все 30000 документов? Это бред, и вы это понимаете.
Решением данной проблемы остаётся модульное разделение разных участков кода на разные файлы. Счётчик Яндекса мы положим в один файл, а счётчик Google в другой. Потом мы создадим отдельный файл шаблон, по которому будут динамически собираться страницы. Поможет нам в этом скриптовый язык PHP и его выражения — include или require.
Разница между выражениями заключается в том, что при ошибке require выдаст фатальную ошибку уровня E_COMPILE_ERROR, а include выдаст предупреждение E_WARNING, которое позволит скрипту продолжить выполнение.
Задача
Нужно научиться подключать файлы в PHP — вставлять содержимое внешнего файла в PHP.
Среда разработки
Для решения этой задачи будем использовать локальную среду разработки — OpenServer. Этот продукт позволяет эмулировать работу реального сайта на домашнем компьютере (не на сервере).
Решение задачи
Мы создадим 4 файла, чтобы убедиться, что «голые» HTML коды подгружаются в один файл PHP без каких-либо проблем. Основной файл, в котором будем собирать содержимое трёх, назовём классически — «index.php». По умолчанию веб-серверы пытаются отыскать в директориях хостинга именно файлы с именем «index«, чтобы загрузить страничку сайта.
Остальные 3 файла будут иметь схожие друг с другом имена: «file1.php«; «file2.php«; «file3.php«.
Для начала в основной файл запишем базовый шаблон кода HTML страницы и добавим элементы, определяющие начало и конец выполнения скрипта PHP.

Файл index.php
В файл «file1.php» запишем HTML заголовок «h2» с содержимым — «Это строка из файла file1.php«.
В файл «file2.php» запишем HTML заголовок «h2» с содержимым — «Это строка из файла file2.php«.
В файл «file3.php» запишем HTML заголовок «h2» с содержимым — «Это строка из файла file3.php«.
![]()
![]()
![]()
Это строка из файла file1.php
Это строка из файла file2.php
Это строка из файла file3.php

Добавление информации о подключении кода трёх файлов в основной файл

Файл index.php
Запустим выполнение файла «index.php» в браузере при активном локальном веб-сервере.

Мы видим чистый HTML одного полноценного документа, который собрался из разных файлов на нашем хостинге. По сути — это самый простой способ применения PHP в разработке, если ты только-только знакомишься с возможностями скриптового языка.
Откроем инструменты разработчика и посмотрим содержимое. Ниже показан собранный основной файл «index.php» из разных PHP-файлов в инструментах разработчика.

Итог
Мы добились решения поставленной задачи и теперь можем разделить PHP документ со сложной структурой на более простые и понятные части в виде отдельных PHP файлов.
В каком случае пригодится знание подключения файлов в PHP
Если вы недавно поняли, что такое HTML и зачем он нужен, если вы попробовали создать своими собственными руками «лендинг пэйдж» на 10 страниц, то вы 100% задались вопросом: «А как можно упростить себе работу над проектом?».
Информация, описанная в этой публикации, приоткрывает дверь на пути в понимании модульности систем управления контента сайта. Уже сейчас вам очевидно, что сложные и большие проекты пишутся не за один день. А это значит, что сайт должен уметь разграничивать зоны ответственности между разработчиками, чтобы не «валить всё в одну кашу» и не загромождать восприятие кода.
Как подгрузить HTML-код из файла силами JavaScript на web-страницу через объект XMLHttpRequest?
Файл index.html обрабатывается силами web-сервера и автоматически загружается в браузер пользователя при обращении к сайту (главной странице).
Файл index.html имеет классическую разметку документа:
DOCTYPE html> html lang="ru"> head> meta charset="UTF-8"> meta name="viewport" content="width=device-width, initial-scale=1.0"> title>Документtitle> head> body> body> html>

Это «пустая» HTML-страница со своим уникальным адресом. На странице визуально нет ничего. Просто белый лист.
Задача
Необходимо на страницу index.html подключить HTML-разметку из файла text.html , но так чтобы файл text.html содержал только HTML-элементы и . То есть мы хотим подгрузить только уникальную информацию на страницу без «лишних» мета-данных.
Также мы хотим сделать эту загрузку в фоне, без перезагрузки страницы index.html . То есть пользователь не увидит в адресной строке браузера другого адреса. Перезагрузки страницы не будет.
Файл text.html имеет разметку:
< h1 >Содержимое файла «text.html»
< p >Меня зовут ТЕКСТ АБЗАЦЕВИЧ. Я пришёл из файла «text.html». Я живу в HTML-элементе «p».

ВНИМАНИЕ! Запросы к серверу мы будем делать ТОЛЬКО через работающий локально веб-сервер. Ознакомьтесь с протоколом CORS и стандартом Fetch. Локальный запуск файла index.html в браузере не приведёт к работающему результату. Используйте бесплатный продукт «OpenServer» для своих тестов.
Предпосылки. Зачем это нужно?
Главная идея задачи — это создание шаблонов генерации документов силами JavaScript, при помощи которых можно лучше управлять визуальным содержимым сайта.
Каждая отдельная страница сайта перестаёт быть статичной (уже собранной). В результате, мы разделяем потенциальную страницу на части. Например:
- Один документ отвечает за шапку сайта
- Другой за подвал
- Третий за основное содержимое
- Четвёртый за боковые панели
- Пятый за рекламные баннеры
- Шестой за галерею фотографий
- Седьмой за контактную информацию
- и т. п..
Решение задачи
Для начала подключим на страницу index.html файл со скриптом, который будет называться gettext.js .
В файле index.html внутри элемента поместим элемент с атрибутом src и его значением gettext.js

Для решения задачи мы будем использовать объект XMLHttpRequest. Стандарт XMLHttpRequest определяет API-интерфейс, который предоставляет клиенту функциональные возможности по сценарию для передачи данных между клиентом и сервером .
Логика работы такая:
- Посылаем запрос на сервер.
- Дожидаемся ответа. Ловим содержимое файла.
- Вносим нужные изменения в документ.
Отредактируем файл gettext.js
var inBody = function()< // Создаём анонимную функцию. Помещаем её в переменную "inBody" var xhr = new XMLHttpRequest() // Создаём локальную переменную XHR, которая будет объектом XMLHttpRequest xhr.open('GET', 'text.html') // Задаём метод запроса и URL запроса xhr.onload = function()< // Используем обработчик событий onload, чтобы поймать ответ сервера XMLHttpRequest console.log(xhr.response) // Выводим в консоль содержимое ответа сервера. Это строка! document.body.innerHTML = xhr.response // Содержимое ответа, помещаем внутрь элемент "body" > xhr.send() // Инициирует запрос. Посылаем запрос на сервер. > inBody() // Запускаем выполнение функции получения содержимого файла

Логика работы объекта XMLHttpRequest
В первой строке мы создаём анонимную функцию и помещаем её в переменную «inBody«. Название переменной описывает решаемую задачу — дословно «вТело«. То есть результатом выполнения этой функции будет интеграция содержимого файла text.html внутрь элемента загруженной странице index.html на клиенте (в браузере)
Со второй строки начинается тело функции. С помощью конструктора объектов мы создаём новый объект XMLHttpRequest и помещаем его в локальную переменную «xhr«. Название переменной означает сокращённую запись от первых трёх букв — X ML H ttp R equest ( XHR ). Т.к. область видимости ограничена родительской функцией, то можно использовать подобное название без опасений. В рабочих проектах не рекомендую использовать глобальные переменные с именем XHR , т. к. на практике такое имя применяется в основном к объектам XMLHttpRequest.
Третья строка запускает метод open() объекта XMLHttpRequest. В этом методе задаётся HTTP-метод запроса и URL-адрес запроса. В нашем случае мы хотим получить содержимое файла по адресу «text.html», который находится в той же директории, что и загруженный в браузер index.html. Получать содержимое мы будем методом «GET» протокола HTTP.
Четвёртая строка описывает логику работы обработчика события onload. Пользовательский агент ДОЛЖЕН отправить событие load, когда реализация DOM завершит загрузку ресурса (такого как документ) и любых зависимых ресурсов (таких как изображения, таблицы стилей или сценарии). То есть обработчиком события onload мы ловим срабатывание типа события load и полученные ресурсы мы достаём при помощи атрибута ответа response объекта XMLHttpRequest.
Пятой строкой мы выводим в консоль результат ответа сервера. Она необходима для разработки. Она не обязательна. ВНИМАНИЕ! Содержимое ответа по-умолчанию имеет тип данных — string (строка). Это стандарт клиент-серверного взаимодействия. Все данные передаются по сети в виде «строковых данных». Так всегда происходит — это норма. Если вы точно знаете каким образом строка будет оформлена, тогда вы можете воспользоваться атрибутом ответа responseType и в этом случае содержимое ответа будет одним из:
- пустая строка (по умолчанию),
- arraybuffer
- blob
- document
- json
- text
В шестой строке мы присваиваем элементу внутренне содержимое пришедшее из файла на сервере. Это содержимое будет заключено между открывающим и закрывающим . XMLHttpRequest имеет связанный ответ response.
Восьмая строка инициирует запрос на сервер методом send() и отправляет его.
На десятой строке мы вызываем функцию «inBody»
Результат работы

Мы видим итоговую страницу с нужным нам содержимым. На favicon не обращаем внимания т. к. браузер Chrome вдруг решил его поискать.
Вкладка имеет название «Документ», которое пришло из элемента .


Главная страница нашего «воображаемого» сайта http://getinnerofpage/ содержит информацию, пришедшую из другого файла.

Разметка итогового документа после выполнения запроса к серверу. Браузер «переварил» строковые данные и преобразовал их в HTML-разметку.

В инструментах разработчика на вкладке Network мы видим последовательность загрузки данных для главной страницы сайта

Сперва браузер запросил HTML-документ главной страницы сайта. Статус 200 — ОК. Потом после разбора разметки браузер загрузил файл со скриптом. Статус 200 — ОК. После этого браузер начал синхронно обрабатывать выполнение инструкций файла скрипта. На восьмой строчке выполнения файла gettext.js мы видим обращение к файлу text.html

Статус 200 — ОК означает успешную подачу запроса — запрашиваемые ресурсы имеются на сервере.

В ответе сервера браузер уже понимает пришедшие данные и подсвечивает HTML-синтаксис, указывая на элементы и . То есть браузер уже сам разобрал пришедший тип данных string и подсветил разработчику открывающиеся и закрывающиеся элементы.
Важно обратить внимание, что на подгрузку данных «в фоне» потребовалось некоторое время. В реальных проектах нужно учитывать эту особенность и правильно распределять зависимости последовательностей отдачи содержимого пользователю.
Может оказаться так, что при формировании финансового графика часть данных не успеет прийти вовремя — это исказит трактование данных из отчёта и навредит бизнесу из-за ошибки вычислений. Будьте внимательны! В таких случаях уместно использовать объект Promise .
Импортировать HTML код из другого файла в код
Вам придется сделать запрос по url и результат запроса вставить в html.
var xhr= new XMLHttpRequest(); xhr.open('GET', 'x.html', true); xhr.onreadystatechange= function() < if (this.readyState!==4) return; if (this.status!==200) return; // or whatever error handling you want document.getElementById('y').innerHTML= this.responseText; >; xhr.send(); $(function() < $('#loadContent').load('page1.html'); >); Отслеживать
ответ дан 16 ноя 2017 в 12:19
1,907 13 13 серебряных знаков 22 22 бронзовых знака
- javascript
- html
-
Важное на Мете
Похожие
Подписаться на ленту
Лента вопроса
Для подписки на ленту скопируйте и вставьте эту ссылку в вашу программу для чтения RSS.
Дизайн сайта / логотип © 2023 Stack Exchange Inc; пользовательские материалы лицензированы в соответствии с CC BY-SA . rev 2023.11.21.1314
Нажимая «Принять все файлы cookie» вы соглашаетесь, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.