Как конвертировать csv в excel в Jupyter Notebook
Ну что, начинаю тут вещать и собирать свои лайфхаки. Без них бы я не разобралась в том, что знаю сейчас.
В Jupyter’е есть как минимум с десяток классных функций упрощающих жизнь всем, для примера возьму импорт и экспорт датафреймов:
Импорт
pd.read_csv(filename) | Загрузить CSV file
pd.read_table(filename) | Из текстового файла с разделителями (например, TSV)
pd.read_excel(filename) | Загрузить Excel file
pd.read_sql(query, connection_object) | Загрузка из таблицы / базы данных SQL
pd.read_json(json_string) | Чтение из строки, URL или файла в формате JSON
pd.read_html(url) | Разбирает html URL, строку или файл и извлекает таблицы в список датафреймов
pd.read_clipboard() | Берет содержимое вашего буфера обмена и передает его в read_table()
pd.DataFrame(dict) | Словарь, ключи для имен столбцов, значения для данных в виде списков
Экспорт
df.to_csv(filename) | Записать в CSV file
df.to_excel(filename) | Записать в Excel file
df.to_sql(table_name, connection_object) | Записать в SQL table
df.to_json(filename) | Записать в JSON format
Сегодня расскажу немножко про боль при сохранении cvs в excel, ключевое почему не срабатывает просто сухое to_excel() — нужно сначала записать данные в эксель, а после сохранять.
Например у вас загружен в Jupyter csv с помощью pd.read_csv(filename)
Ниже будет перевод материала из вот этой статьи на медиуме, спасибо @Stephen Fordham.
У Стивена очень подробно все описано, даже с примером как в файл сохранить несколько датафреймов в разные вкладки. Я же представлю скрин того, как сохранить один датафрейм.
Опишу то что мы видим, чтобы использовать Pandas для записи объектов Dataframe в Excel, необходимо установить 2 библиотеки. Это библиотеки xlrd и openpyxl соответственно. Для удобства эти библиотеки можно установить, не выходя из Jupyter Notebook, просто добавив к команде префикс ! подписать с последующей установкой pip . Когда эта ячейка будет выполнена, вывод будет либо «Требование уже выполнено», либо установка будет выполнена автоматически.
Отвечаю на вопрос, почему у меня на скрине ! pip install openpyxl==3.0.1
При установке последней версии методом ! pip install openpyxl (ставится последняя версия 3.0.2) у меня возникает ошибка при выполнении сохранения TypeError: got invalid input value of type , expected string or Element
Собственно вопрос решается если ставить версию ниже
Далее все проще, как пишет Стивен в своей публикации — От Pandas Dataframe к Excel за 3 шага
- Чтобы начать процесс экспорта Pandas Dataframes в Excel, необходимо создать объект ExcelWriter. Это достигается с помощью метода ExcelWriter, который вызывается непосредственно из библиотеки панд. В этом методе я указываю имя файла Excel (в статье по ссылке автор выбрал Tennis_players, у меня же вы найдете games) и включаю расширение .xlsx. Этот шаг создает основную книгу экселя, в которую мы можем затем записать наши датафреймы.
- После этого я вызываю метод .to_excel на скрине выше. В методе .to_excel первым аргументом, который нужно указать, является объект ExcelWriter, за которым следует необязательный параметр имя листа. (я не использовала индекс, но в статье, на которую я ссылаюсь устанавливают аргумент index =False, по умолчанию, кстати, идет True) Проставляем аргумент ‘utf-8’ для параметра encoding для обработки любых специальных символов. Тоже самое можно повторить и для других датафреймов, единственное записывать их в разные листы, параметр sheet_name.
- Наконец, теперь, когда наши датафреймы поставлены в очередь для экспорта, мы вызываем метод save для объекта ExcelWriter, который мы назначили переменной my_excel_file.
Основы Pandas №1 // Чтение файлов, DataFrame, отбор данных
Pandas — одна из самых популярных библиотек Python для аналитики и работы с Data Science. Это как SQL для Python. Все потому, что pandas позволяет работать с двухмерными таблицами данных в Python. У нее есть и масса других особенностей. В этой серии руководств по pandas вы узнаете самое важное (и часто используемое), что необходимо знать аналитику или специалисту по Data Science. Это первая часть, в которой речь пойдет об основах.
Примечание: это практическое руководство, поэтому рекомендуется самостоятельно писать код, повторяя инструкции!
Чтобы разобраться со всем, необходимо…
- Установить Python3.7+, numpy и Pandas.
- Следующий шаг: подключиться к серверу (или локально) и запустить Jupyter. Затем открыть Jupyter Notebook в любимом браузере. Создайте новый ноутбук с именем «pandas_tutorial_1».
- Импортировать numpy и pandas в Jupyter Notebook с помощью двух строк кода:
import numpy as np import pandas as pd Примечание: к «pandas» можно обращаться с помощью аббревиатуры «pd». Если в конце инструкции с import есть as pd , Jupyter Notebook понимает, что в будущем, при вводе pd подразумевается именно библиотека pandas.
Теперь все настроено! Переходим к руководству по pandas! Первый вопрос:
Как открывать файлы с данными в pandas
Информация может храниться в файлах .csv или таблицах SQL. Возможно, в файлах Excel. Или даже файлах .tsv. Или еще в каком-то другом формате. Но цель всегда одна и та же. Если необходимо анализировать данные с помощью pandas, нужна структура данных, совместимая с pandas.
Структуры данных Python
В pandas есть два вида структур данных: Series и DataFrame.
Series в pandas — это одномерная структура данных («одномерная ndarray»), которая хранит данные. Для каждого значения в ней есть уникальный индекс.
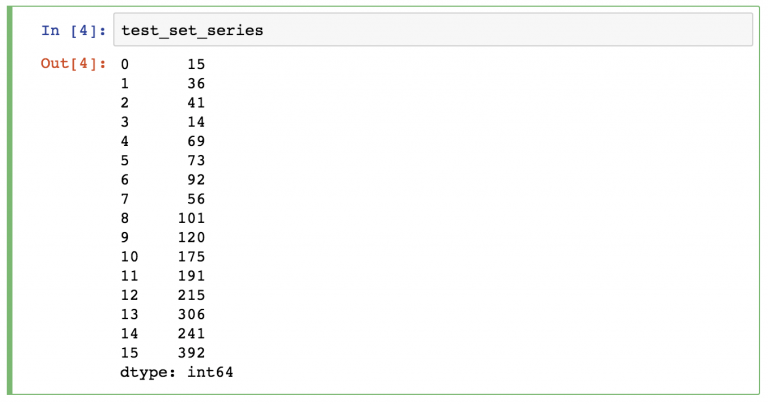
DataFrame — двухмерная структура, состоящая из колонок и строк. У колонок есть имена, а у строк — индексы.
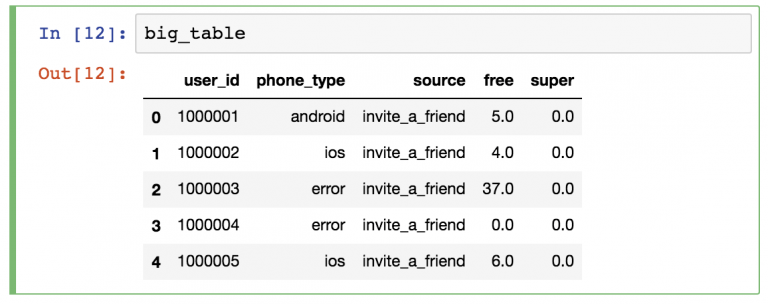
В руководстве по pandas основной акцент будет сделан на DataFrames. Причина проста: с большей частью аналитических методов логичнее работать в двухмерной структуре.
Загрузка файла .csv в pandas DataFrame
Для загрузки .csv файла с данными в pandas используется функция read_csv() .
Начнем с простого образца под названием zoo. В этот раз для практики вам предстоит создать файл .csv самостоятельно. Вот сырые данные:
animal,uniq_id,water_need elephant,1001,500 elephant,1002,600 elephant,1003,550 tiger,1004,300 tiger,1005,320 tiger,1006,330 tiger,1007,290 tiger,1008,310 zebra,1009,200 zebra,1010,220 zebra,1011,240 zebra,1012,230 zebra,1013,220 zebra,1014,100 zebra,1015,80 lion,1016,420 lion,1017,600 lion,1018,500 lion,1019,390 kangaroo,1020,410 kangaroo,1021,430 kangaroo,1022,410 Вернемся во вкладку “Home” https://you_ip:you_port/tree Jupyter для создания нового текстового файла…
затем скопируем данные выше, чтобы вставить информацию в этот текстовый файл…
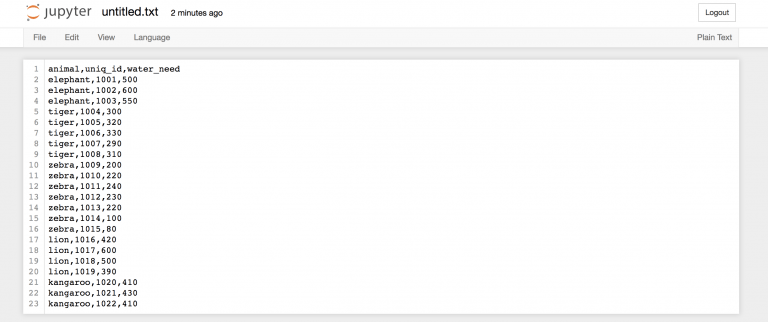
…и назовем его zoo.csv!
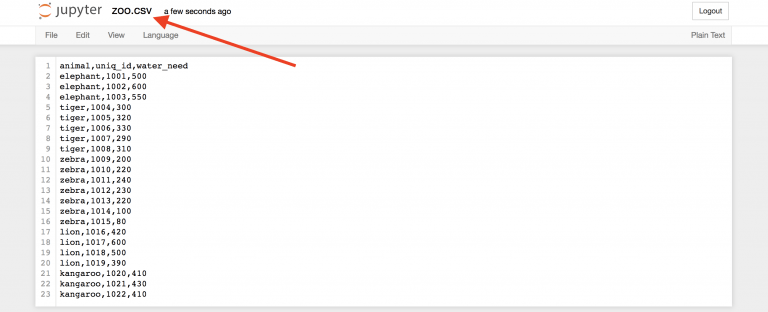
Это ваш первый .csv файл.
Вернемся в Jupyter Notebook (который называется «pandas_tutorial_1») и откроем в нем этот .csv файл!
Для этого нужна функция read_csv()
Введем следующее в новую строку:
pd.read_csv('zoo.csv', delimiter=',') 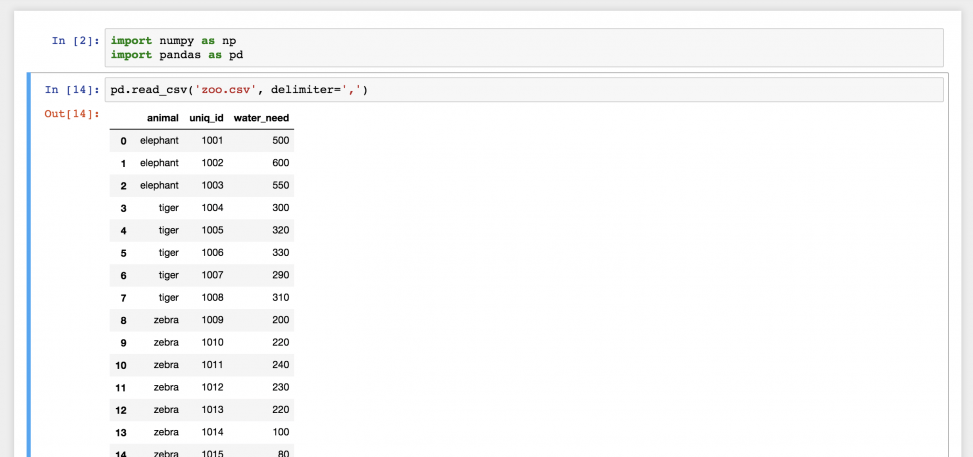
Готово! Это файл zoo.csv , перенесенный в pandas. Это двухмерная таблица — DataFrame. Числа слева — это индексы. А названия колонок вверху взяты из первой строки файла zoo.csv.
На самом деле, вам вряд ли придется когда-нибудь создавать .csv файл для себя, как это было сделано в примере. Вы будете использовать готовые файлы с данными. Поэтому нужно знать, как загружать их на сервер!
Вот небольшой набор данных: ДАННЫЕ
Если кликнуть на ссылку, файл с данными загрузится на компьютер. Но он ведь не нужен вам на ПК. Его нужно загрузить на сервер и потом в Jupyter Notebook. Для этого нужно всего два шага.
Шаг 1) Вернуться в Jupyter Notebook и ввести эту команду:
!wget https://pythonru.com/downloads/pandas_tutorial_read.csv Это загрузит файл pandas_tutorial_read.csv на сервер. Проверьте:
Если кликнуть на него…
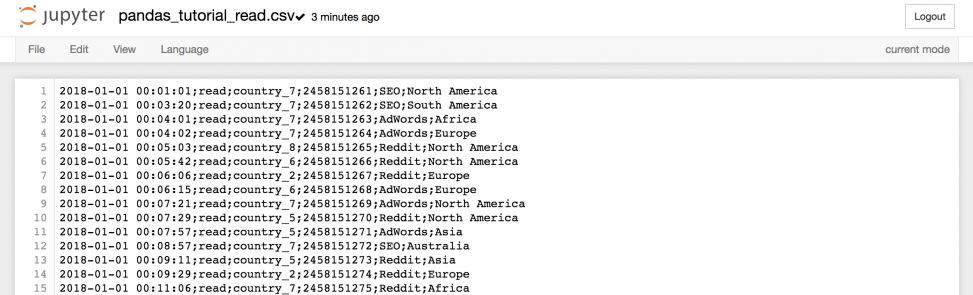
…можно получить всю информацию из файла.
Шаг 2) Вернуться в Jupyter Notebook и использовать ту же функцию read_csv (не забыв поменять имя файла и значение разделителя):
pd.read_csv('pandas_tutorial_read.csv', delimete=';') Данные загружены в pandas!
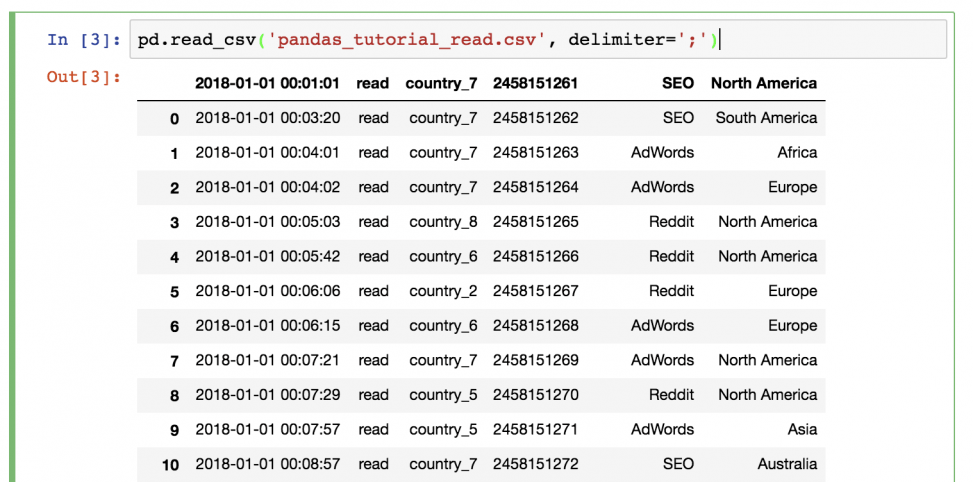
Что-то не так? В этот раз не было заголовка, поэтому его нужно настроить самостоятельно. Для этого необходимо добавить параметры имен в функцию!
pd.read_csv('pandas_tutorial_read.csv', delimiter=';', names=['my_datetime', 'event', 'country', 'user_id', 'source', 'topic']) 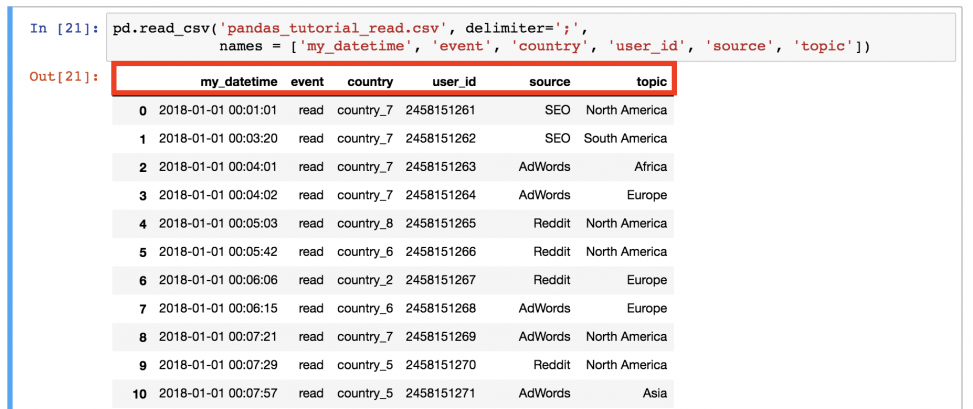
Так лучше!
Теперь файл .csv окончательно загружен в pandas DataFrame .
Примечание: есть альтернативный способ. Вы можете загрузить файл .csv через URL напрямую. В этом случае данные не загрузятся на сервер данных.
pd.read_csv( 'https://pythonru.com/downloads/pandas_tutorial_read.csv', delimiter=';', names=['my_datetime', 'event', 'country', 'user_id', 'source', 'topic'] ) Примечание: если вам интересно, что в этом наборе, то это лог данных из блога о путешествиях. Ну а названия колонок говорят сами за себя.
Отбор данных из dataframe в pandas
Это первая часть руководства, поэтому начнем с самых простых методов отбора данных, а уже в следующих углубимся и разберем более сложные.
Вывод всего dataframe
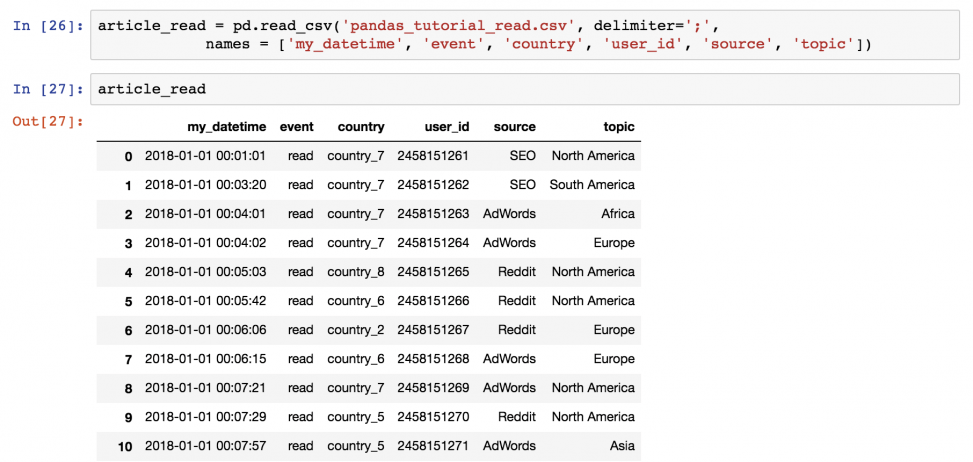
Базовый метод — вывести все данные из dataframe на экран. Для этого не придется запускать функцию pd.read_csv() снова и снова. Просто сохраните денные в переменную при чтении!
article_read = pd.read_csv( 'pandas_tutorial_read.csv', delimiter=';', names = ['my_datetime', 'event', 'country', 'user_id', 'source', 'topic'] ) После этого можно будет вызывать значение article_read каждый раз для вывода DataFrame!
Вывод части dataframe
Иногда удобно вывести не целый dataframe, заполнив экран данными, а выбрать несколько строк. Например, первые 5 строк можно вывести, набрав:
article_read.head() 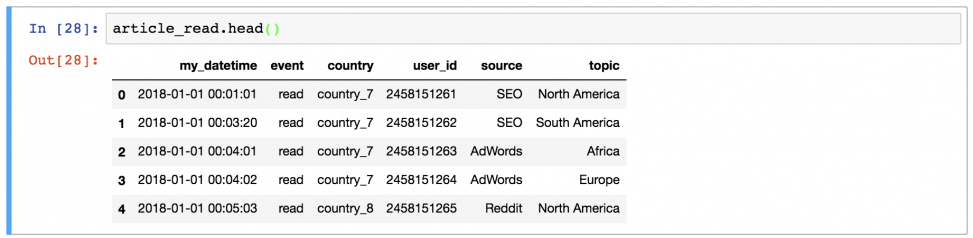
Или последние 5 строк:
article_read.tail() 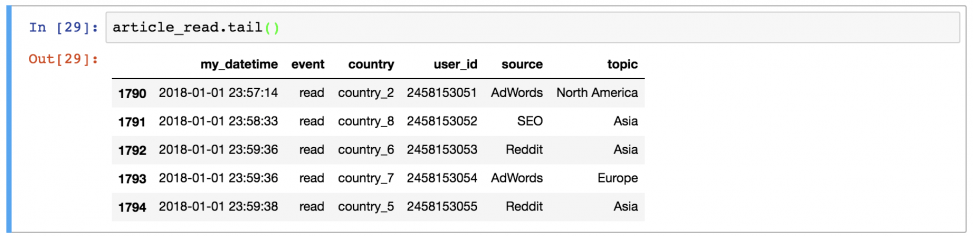
Или 5 случайных строк:
article_read.sample(5) 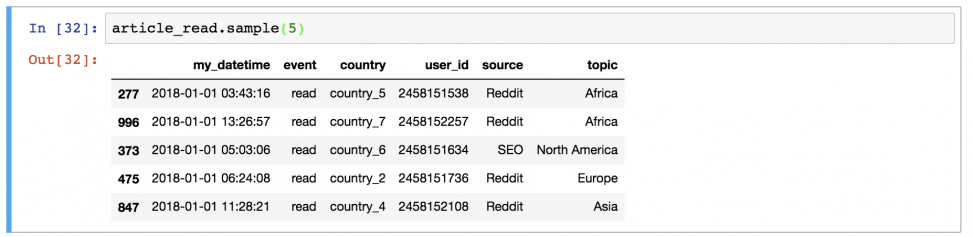
Вывод определенных колонок из dataframe
А это уже посложнее! Предположим, что вы хотите вывести только колонки «country» и «user_id».
Для этого нужно использовать команду в следующем формате:
article_read[['country', 'user_id']] 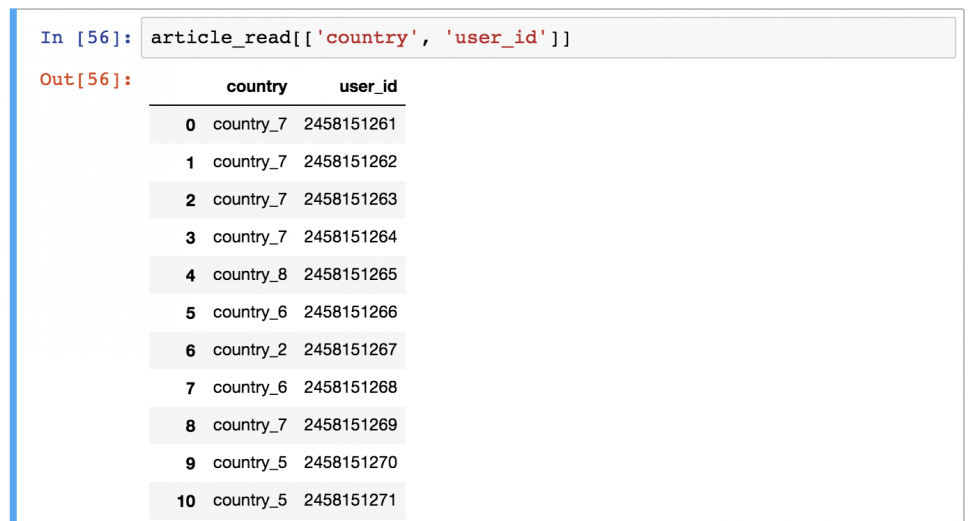
Есть предположения, почему здесь понадобились двойные квадратные скобки? Это может показаться сложным, но, возможно, так удастся запомнить: внешние скобки сообщают pandas, что вы хотите выбрать колонки, а внутренние — список (помните? Списки в Python указываются в квадратных скобках) имен колонок.
Поменяв порядок имен колонов, изменится и результат вывода.
Это DataFrame выбранных колонок.
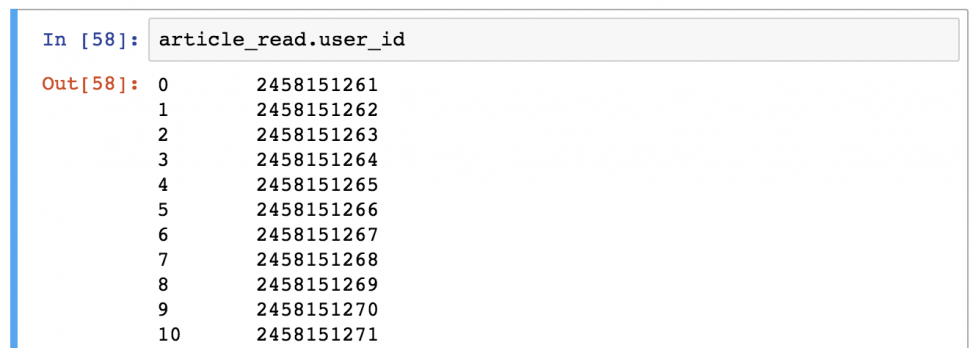
Примечание: иногда (особенно в проектах аналитического прогнозирования) нужно получить объекты Series вместе DataFrames. Это можно сделать с помощью одного из способов:
- article_read.user_id
- article_read[‘user_id’]
Фильтрация определенных значений в dataframe
Если прошлый шаг показался сложным, то этот будет еще сложнее!
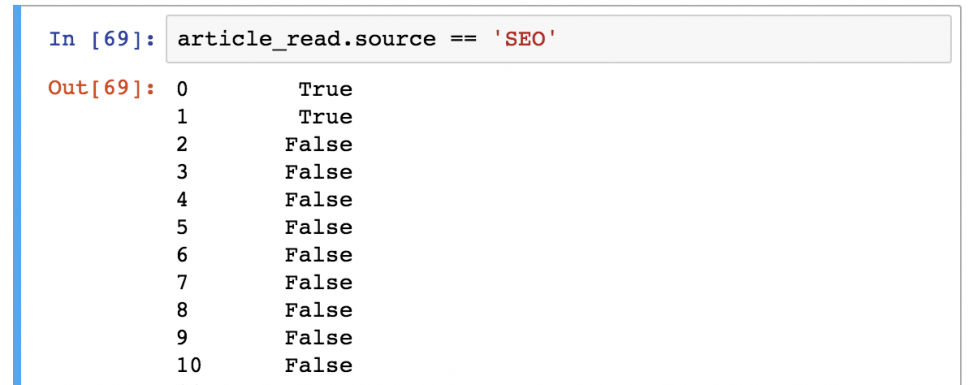
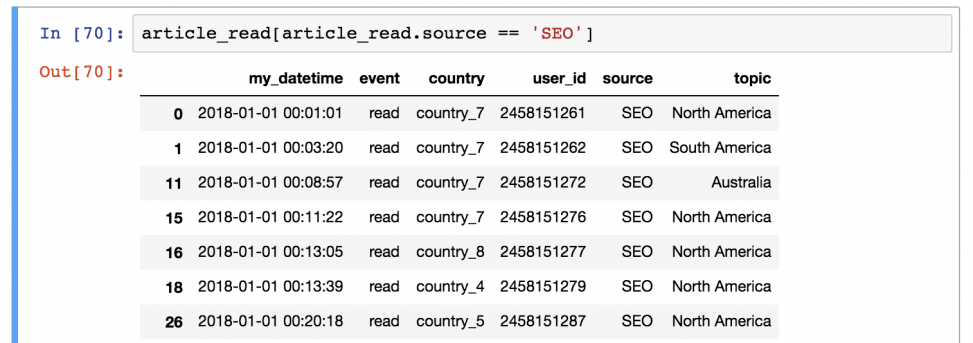
Предположим, что вы хотите сохранить только тех пользователей, которые представлены в источнике «SEO». Для этого нужно отфильтровать по значению «SEO» в колонке «source»:
article_read[article_read.source == 'SEO'] Важно понимать, как pandas работает с фильтрацией данных:
Шаг 1) В первую очередь он оценивает каждую строчку в квадратных скобках: является ли ‘SEO’ значением колонки article_read.source ? Результат всегда будет булевым значением ( True или False ).
Шаг 2) Затем он выводит каждую строку со значением True из таблицы article_read .
Выглядит сложно? Возможно. Но именно так это и работает, поэтому просто выучите, потому что пользоваться этим придется часто!
Функции могут использоваться одна за другой
Важно понимать, что логика pandas очень линейна (как в SQL, например). Поэтому если вы применяете функцию, то можете применить другую к ней же. В таком случае входящие данные последней функции будут выводом предыдущей.
Например, объединим эти два метода перебора:
article_read.head()[['country', 'user_id']] Первая строчка выбирает первые 5 строк из набора данных. Потом она выбирает колонки «country» и «user_id».
Можно ли получить тот же результат с иной цепочкой функций? Конечно:
article_read[['country', 'user_id']].head() В этом случае сначала выбираются колонки, а потом берутся первые 5 строк. Результат такой же — порядок функций (и их исполнение) отличается.
А что будет, если заменить значение «article_read» на оригинальную функцию read_csv():
pd.read_csv( 'pandas_tutorial_read.csv', delimiter=';', names = ['my_datetime', 'event', 'country', 'user_id', 'source', 'topic'] )[['country', 'user_id']].head() Так тоже можно, но это некрасиво и неэффективно. Важно понять, что работа с pandas — это применение функций и методов один за одним, и ничего больше.
Проверьте себя!
Как обычно, небольшой тест для проверки! Выполните его, чтобы лучше запомнить материал!
Выберите used_id , country и topic для пользователей из country_2 . Выведите первые 5 строк!
А вот и решение!
Его можно преподнести одной строкой:
article_read[article_read.country == 'country_2'][['user_id','topic', 'country']].head() Или, чтобы было понятнее, можно разбить на несколько строк:
ar_filtered = article_read[article_read.country == 'country_2'] ar_filtered_cols = ar_filtered[['user_id','topic', 'country']] ar_filtered_cols.head() В любом случае, логика не отличается. Сначала берется оригинальный dataframe ( article_read ), затем отфильтровываются строки со значением для колонки country — country_2 ( [article_read.country == ‘country_2’] ). Потому берутся три нужные колонки ( [[‘user_id’, ‘topic’, ‘country’]] ) и в конечном итоге выбираются только первые пять строк ( .head() ).
Итого
Вот и все. В следующей статье вы узнаете больше о разных методах агрегации (например, sum, mean, max, min) и группировки.
Как загрузить файл csv с кириллицей в Jupyter notebook?
sazhyk, Мое решение: изначально надо файл сохранить в utf-8, потом как csv и все работает.

но есть новая проблема: при выводе данных добавляются нули после точки.
вопрос как их убрать.
те мне надо на выходе иметь: 2.26, 1.02. без лишних нулей
Dmitry, слишком мало входных данных вопроса. я же не знаю как вы получаете эти данные.
Dmitry @provocatorr Автор вопроса
import pandas as pd lists_and_loops_data_3 = pd.read_csv('lists_and_loops_data_3.csv') lists_and_loops_data_3Dmitry, я так понимаю, в исходных данных так и есть, и эти цифры импортируются как строки. Вы их сделайте типом float и работайте как с вещественными числами. Ну или используйте decimal. Там где надо можно округлить наверное.
Dmitry @provocatorr Автор вопроса
sazhyk, проблема в том что в файле есть цифра 2.26 а после импорта она становится 2.2600. Вопрос: как прописать импорт правильно чтоб было полное совпадение?
Как импортировать файл формата csv в python (panda)?
На что получил ошибку.
Пробовал закидывать файл в папку pandas (подпапка анаконды), не помогло. Пробовал также загрузить файл в окне стартовой страницы Jupiter- тоже не помогло. Ч.Я.Д.Н.Т.?
- Вопрос задан более трёх лет назад
- 2732 просмотра
1 комментарий
Простой 1 комментарий
Вам нужно прописать адрес расположения файла 131.csv или положить его в директорию, где находится файл Jupiter notebook..
Решения вопроса 1

Получил ошибку — нормально.
Скрыл её от нас — нехорошо.
Как мы тебе поможем?
Ответ написан более трёх лет назад
Нравится 3 4 комментария
Вениамин Белоусов @Venuhaha Автор вопроса
Просто мне казалось что я изначально делаю что-то не так. Так как в учебнике вообще этому не уделяется внимание, как 2+2. Не могу понять, как ему показать где лежит файл. Вообще все странно. Согласно учебнику- я пишу две строки кода и все.
Вот ошибка-
spoiler
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) in () 1 import pandas ----> 2 data = pandas . read_csv ( "titanic.csv " , index_col="PassengerId " ) D:\Anaconda\lib\site-packages\pandas\io\parsers.py in parser_f(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, escapechar, comment, encoding, dialect, tupleize_cols, error_bad_lines, warn_bad_lines, skipfooter, skip_footer, doublequote, delim_whitespace, as_recarray, compact_ints, use_unsigned, low_memory, buffer_lines, memory_map, float_precision) 653 skip_blank_lines=skip_blank_lines) 654 --> 655 return _read(filepath_or_buffer, kwds) 656 657 parser_f.__name__ = name D:\Anaconda\lib\site-packages\pandas\io\parsers.py in _read(filepath_or_buffer, kwds) 409 410 try: --> 411 data = parser.read(nrows) 412 finally: 413 parser.close() D:\Anaconda\lib\site-packages\pandas\io\parsers.py in read(self, nrows) 1003 raise ValueError('skipfooter not supported for iteration') 1004 -> 1005 ret = self._engine.read(nrows) 1006 1007 if self.options.get('as_recarray'): D:\Anaconda\lib\site-packages\pandas\io\parsers.py in read(self, nrows) 1824 1825 names, data = self._do_date_conversions(names, data) -> 1826 index, names = self._make_index(data, alldata, names) 1827 1828 # maybe create a mi on the columns D:\Anaconda\lib\site-packages\pandas\io\parsers.py in _make_index(self, data, alldata, columns, indexnamerow) 1333 1334 elif not self._has_complex_date_col: -> 1335 index = self._get_simple_index(alldata, columns) 1336 index = self._agg_index(index) 1337 D:\Anaconda\lib\site-packages\pandas\io\parsers.py in _get_simple_index(self, data, columns) 1367 index = [] 1368 for idx in self.index_col: -> 1369 i = ix(idx) 1370 to_remove.append(i) 1371 index.append(data[i]) D:\Anaconda\lib\site-packages\pandas\io\parsers.py in ix(col) 1361 if not isinstance(col, compat.string_types): 1362 return col -> 1363 raise ValueError('Index %s invalid' % col) 1364 index = None 1365 ValueError: Index PassengerId invalid