Руководство по Jupyter Notebook для начинающих
Jupyter Notebook — это мощный инструмент для разработки и представления проектов Data Science в интерактивном виде. Он объединяет код и вывод все в виде одного документа, содержащего текст, математические уравнения и визуализации.
Такой пошаговый подход обеспечивает быстрый, последовательный процесс разработки, поскольку вывод для каждого блока показывается сразу же. Именно поэтому инструмент стал настолько популярным в среде Data Science за последнее время. Большая часть Kaggle Kernels (работы участников конкурсов на платформе Kaggle) сегодня созданы с помощью Jupyter Notebook.
Этот материал предназначен для новичков, которые только знакомятся с Jupyter Notebook, и охватывает все этапы работы с ним: установку, азы использования и процесс создания интерактивного проекта Data Science.
Настройка Jupyter Notebook
Чтобы начать работать с Jupyter Notebook, библиотеку Jupyter необходимо установить для Python. Проще всего это сделать с помощью pip:
pip3 install jupyter Лучше использовать pip3 , потому что pip2 работает с Python 2, поддержка которого прекратится уже 1 января 2020 года.
Теперь нужно разобраться с тем, как пользоваться библиотекой. С помощью команды cd в командной строке (в Linux и Mac) в первую очередь нужно переместиться в папку, в которой вы планируете работать. Затем запустите Jupyter с помощью следующей команды:
jupyter notebook Это запустит сервер Jupyter, а браузер откроет новую вкладку со следующим URL: https://localhost:8888/tree. Она будет выглядеть приблизительно вот так:
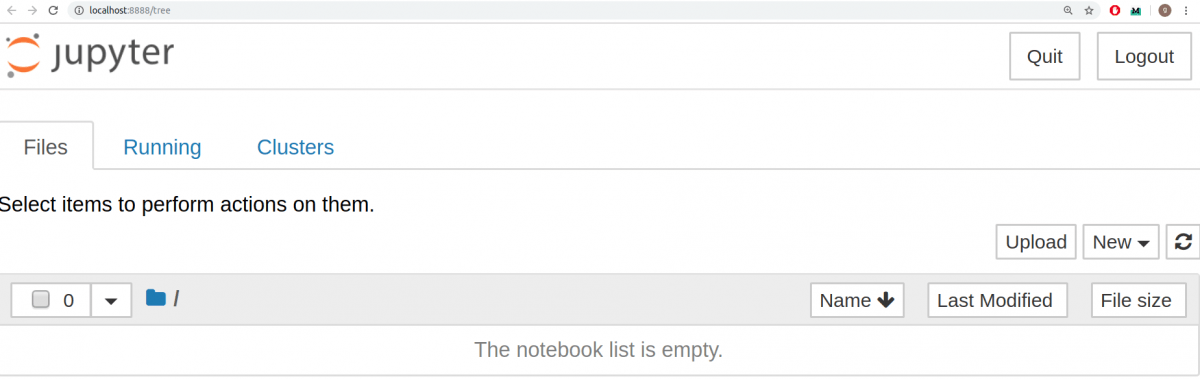
Отлично. Сервер Jupyter работает. Теперь пришло время создать первый notebook и заполнять его кодом.
Основы Jupyter Notebook
Для создания notebook выберите «New» в верхнем меню, а потом «Python 3». Теперь страница в браузере будет выглядеть вот так:
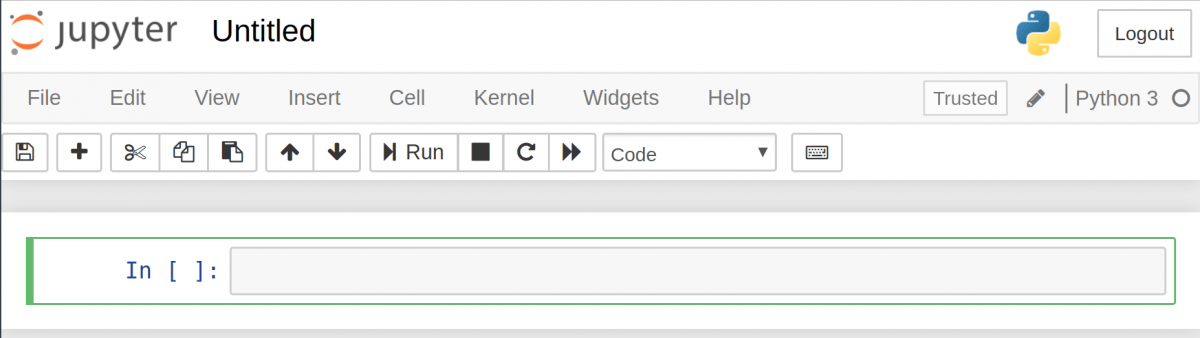
Обратите внимание на то, что в верхней части страницы, рядом с логотипом Jupyter, есть надпись Untitled — это название notebook. Его лучше поменять на что-то более понятное. Просто наведите мышью и кликните по тексту. Теперь можно выбрать новое название. Например, George’s Notebook .
Теперь напишем какой-нибудь код!
Перед первой строкой написано In [] . Это ключевое слово значит, что дальше будет ввод. Попробуйте написать простое выражение вывода. Не забывайте, что нужно пользоваться синтаксисом Python 3. После этого нажмите «Run».
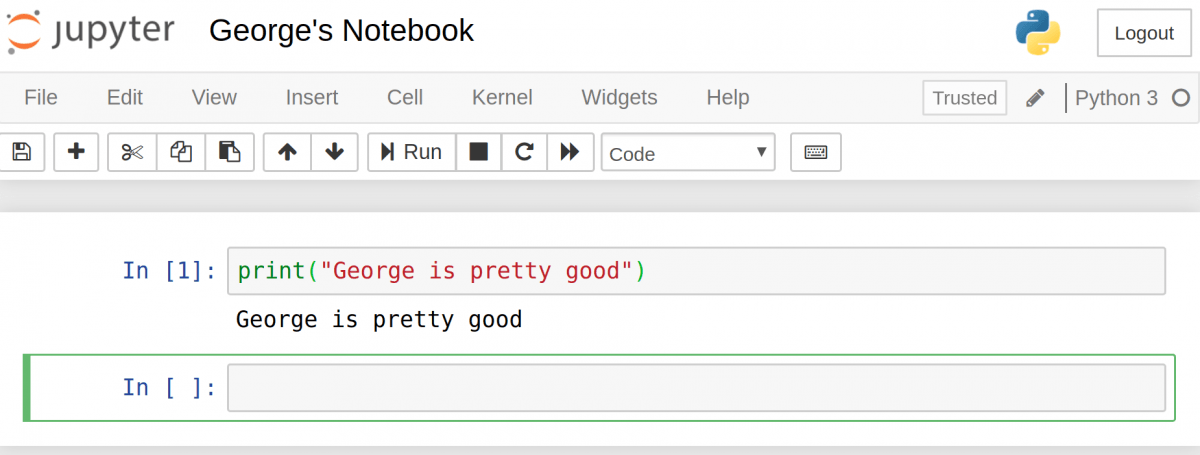
Вывод должен отобразиться прямо в notebook. Это и позволяет заниматься программированием в интерактивном формате, имея возможность отслеживать вывод каждого шага.
Также обратите внимание на то, что In [] изменилась и вместе нее теперь In [1] . Число в скобках означает порядок, в котором эта ячейка будет запущена. В первой цифра 1 , потому что она была первой запущенной ячейкой. Каждую ячейку можно запускать индивидуально и цифры в скобках будут менять соответственно.
Рассмотрим пример. Настроим 2 ячейки, в каждой из которых будет разное выражение print . Сперва запустим вторую, а потом первую. Можно увидеть, как в результате цифры в скобках меняются.
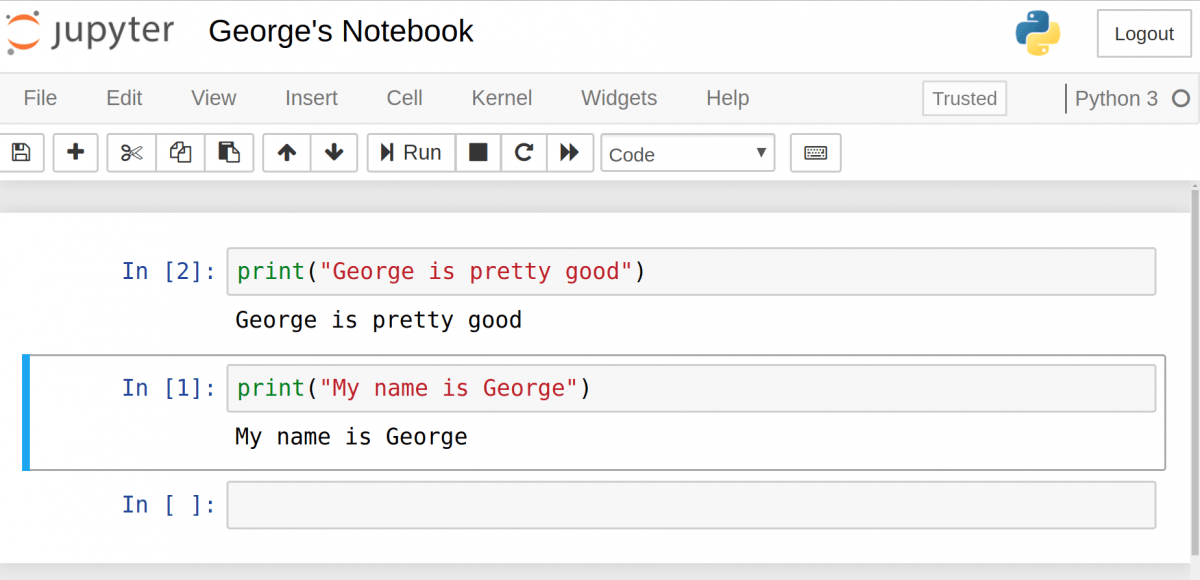
Если есть несколько ячеек, то между ними можно делиться переменными и импортами. Это позволяет проще разбивать весь код на связанные блоки, не создавая переменную каждый раз. Главное убедиться в запуске ячеек в правильном порядке, чтобы переменные не использовались до того, как были созданы.
Добавление описания к notebook
В Jupyter Notebook есть несколько инструментов, используемых для добавления описания. С их помощью можно не только оставлять комментарии, но также добавлять заголовки, списки и форматировать текст. Это делается с помощью Markdown.
Первым делом нужно поменять тип ячейки. Нажмите на выпадающее меню с текстом «Code» и выберите «Markdown». Это поменяет тип ячейки.
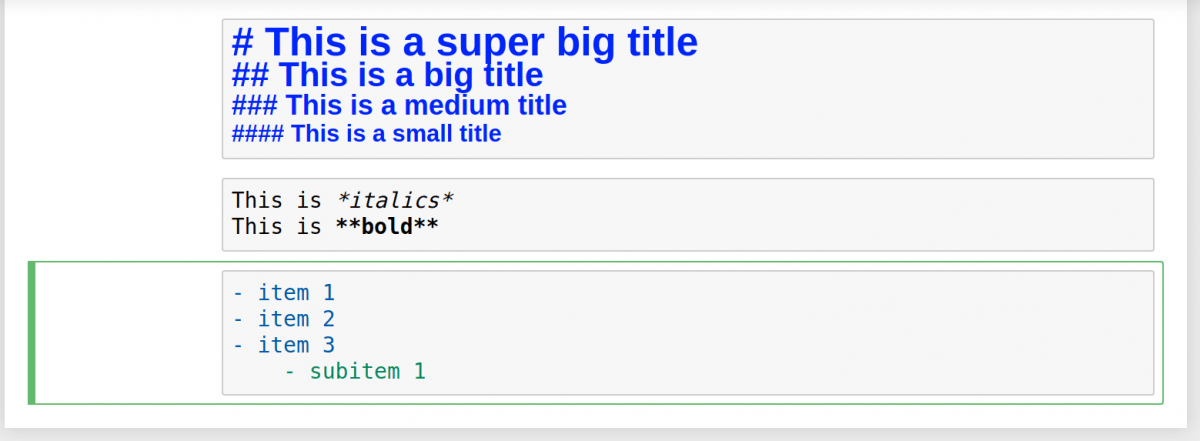
Попробуем несколько вариантов. Заголовки можно создавать с помощью символа # . Один такой символ создаст самый крупный заголовок верхнего уровня. Чем больше # , тем меньше будет текст.
Сделать текст курсивным можно с помощью символов * с двух сторон текста. Если с каждой стороны добавить по два * , то текст станет полужирным. Список создается с помощью тире и пробела для каждого пункта.
Интерактивная наука о данных
Соорудим простой пример проекта Data Science. Этот notebook и код взяты из реального проекта.
Начнем с ячейки Markdown с самым крупным текстом, который делается с помощью одного # . Затем список и описание всех библиотек, которые необходимо импортировать.
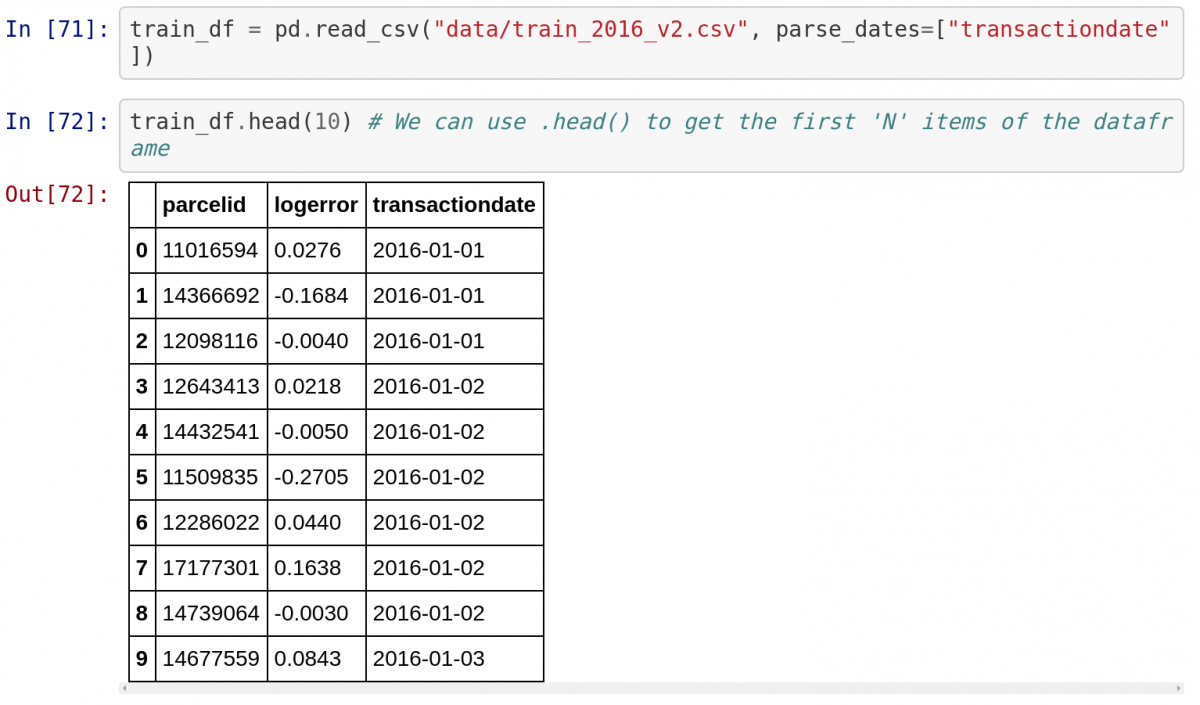
Следом идет первая ячейка, в которой происходит импорт библиотек. Это стандартный код для Python Data Science с одним исключение: чтобы прямо видеть визуализации Matplotlib в notebook, нужна следующая строчка: %matplotlib inline .

Следом нужно импортировать набор данных из файла CSV и вывести первые 10 пунктов. Обратите внимание, как Jupyter автоматически показывает вывод функции .head() в виде таблицы. Jupyter отлично работает с библиотекой Pandas!
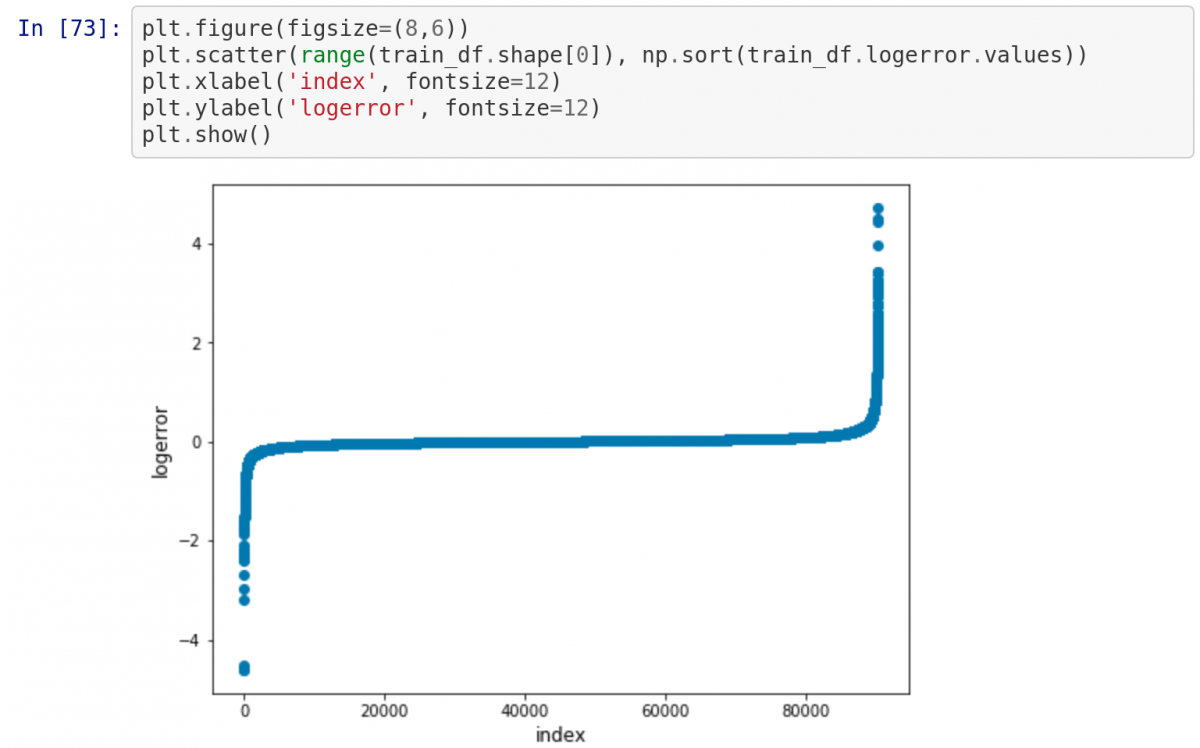
Теперь нарисуем диаграмму прямо в notebook. Поскольку наверху есть строка %matplotlib inline , при написании plt.show() диаграмма будет выводиться в notebook!
Также обратите внимание на то, как переменные из предыдущих ячеек, содержащие данные из CSV-файла, используются в последующих ячейках в том случае, если по отношению к первым была нажата кнопка «Run».
Это простейший способ создания интерактивного проекта Data Science!
Меню
На сервере Jupyter есть несколько меню, с помощью которых от проекта можно получить максимум. С их помощью можно взаимодействовать с notebook, читать документацию популярных библиотек Python и экспортировать проект для последующей демонстрации.
Файл (File): отвечает за создание, копирование, переименование и сохранение notebook в файл. Самый важный пункт в этом разделе — выпадающее меню Download , с помощью которого можно скачать notebook в разных форматах, включая pdf, html и slides для презентаций.
Редактировать (Edit): используется, чтобы вырезать, копировать и вставлять код. Здесь же можно поменять порядок ячеек, что понадобится для демонстрации проекта.
Вид (View): здесь можно настроить способ отображения номеров строк и панель инструментов. Самый примечательный пункт — Cell Toolbar , к каждой ячейке можно добавлять теги, заметки и другие приложения. Можно даже выбрать способ форматирования для ячейки, что потребуется для использования notebook в презентации.
Вставить (Insert): для добавления ячеек перед или после выбранной.
Ячейка (Cell): отсюда можно запускать ячейки в определенном порядке или менять их тип.
Помощь (Help): в этом разделе можно получить доступ к важной документации. Здесь же упоминаются горячие клавиши для ускорения процесса работы. Наконец, тут можно найти ссылки на документацию для самых важных библиотек Python: Numpy, Scipy, Matplotlib и Pandas.
Действия с библиотеками в образах Jupyter Server
В каждом образе Jupyter Server и базовом образе для задач обучения есть предустановленный набор библиотек (см. Библиотеки в образах для Jupyter Server , Библиотеки в образах ).
- Узнать список установленных библиотек.
- Установить дополнительные библиотеки.
- Обновить версии существующих библиотек.
Получение списка библиотек, установленных в образе Jupyter Server
Чтобы увидеть список библиотек, установленных в образе Jupyter Server:
- Создайте или подключитесь к уже существующему Jupyter Notebook.
- В ячейке ноутбука выполните следующую команду:
pip list
Получение списка библиотек, установленных в базовом образе
Чтобы увидеть список библиотек, установленных в базовых образах, выполните последовательность действий, как описано в разделе Актуализация списка библиотек в базовых образах .
Установка дополнительных библиотек в Jupyter Server
Для установки дополнительных библиотек в ячейке ноутбука выполните команду:
!pip install
Где package_name — наименование библиотеки, которую предполагается установить, а version — версия данной библиотеки.
После установки библиотеки выполните следующую команду для проверки:
!pip list | grep
В Jupyter Server есть каталоги, в которых хранятся служебные и пользовательские файлы:
- /home/user — каталог, уникальный для каждого Jupyter Server.
- /home/jovyan — каталог, общий для всех Jupyter Server, созданных в рамках одного воркспейса.
Если устанавливать библиотеки с помощью команды pip install , то зависимости будут установлены в каталог /home/jovyan/.img-xxxxx .
При постановке Jupyter Server на паузу этот каталог остается, при остановке (удалении) каталог удаляется. При удалении Jupyter Server все библиотеки, которые установлены с помощью команды pip install , удаляются вместе с каталогом /home/user .
Для использования требуемого набора библиотек можно создать и использовать кастомный Docker-образ. Подробнее см. Установка необходимых библиотек .
Jupyter Server называется test-img-dir , в нем командой pip install glances установили библиотеку. Установленная библиотека с требуемыми зависимостями будет находиться в каталоге /home/jovyan/.imgenv-test-img-dir-0/lib/python3.7/site-packages .
Обратите внимание на то, что в образ Jupyter Server jupyter-cuda10.1-tf2.3.0-gpu можно дополнительно установить библиотеку DeepSpeed. Для этого:
- Создайте или подключитесь к уже существующему Jupyter Notebook.
- Запустите командную строку ( New → Terminal ).
- Выполните команду ниже. Библиотека установится в соответствующий каталог.
cd /tmp && git clone https://github.com/microsoft/DeepSpeed.git && cd DeepSpeed && \ pip install cpufeature && \ DS_BUILD_SPARSE_ATTN=1 DS_BUILD_CPU_ADAM=1 /tmp/DeepSpeed/install.sh
Установка дополнительных библиотек в базовый образ
Пользователи могут установить дополнительные библиотеки в базовые образы. Для сборки таких кастомных образов используются средства функции client_lib . Подробнее см. Установка необходимых библиотек .
Обновление версий библиотек в Jupyter Server
Чтобы обновить версию установленной библиотеки, выполните команду:
pip install --upgrade
Ранее установленная версия библиотеки обновится.
Пример переустановки версии torch приведен ниже.
pip install --no-cache-dir torch===1.5.0+cu101 torchvision==0.6.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html
Не рекомендуется менять версию базовых пакетов — Horovod, TensorFlow, Apex, MXNet, TensorBoard, KServe, PyTorch.
Обновление версий библиотек в базовых образах
Для обновления версий библиотек, установленных в базовом образе, внесите модули и их версии в файл requirements.txt и соберите кастомный образ с использованием этого файла. Подробнее см. Установка необходимых библиотек .
Актуализация списка библиотек в базовых образах
Список базовых образов и версий предустановленных библиотек в данных образах может периодически обновляться (См. Образы для Jupyter Server ). Пользователи могут получить перечень актуальных версий библиотек. Для этого необходимо выполнить последовательность действий, описанную ниже.
- Создайте или подключитесь к уже существующему Jupyter Notebook.
- Выберите подключение к Jupyter Notebook или JupyterLab. Рабочий каталог, из которого будут запускаться файлы, — /home/jovyan/ .
- Создайте в рабочем каталоге файл test.py следующего содержания:
import subprocess if __name__ == '__main__': cmd = 'pip freeze' subprocess.run(cmd, shell=True)
Важно Импорт функции client_lib в образе jupyter-server:0.0.88 осуществляется командой:
from mlspace.jobs import client_lib
import client_lib
job = client_lib.Job(base_image='your base image', script = '/home/jovyan/test.py', n_workers=1, instance_type='your isntance_type', processes_per_worker=1 )
Для получения значения instance_type воспользуйтесь инструкцией .
job.submit()
import time while True: job.logs() time.sleep(5)
Автоматический импорт библиотек в IPython или Jupyter Notebook
Если вы — частый пользователь IPython или Jupyter Notebooks и вам надоело постоянно импортировать одни и те же библиотеки, то попробуйте этот способ:
- Перейдите к ~/.ipython/profile_default
- Создайте папку startup , если она отсутствует
- Добавьте новый файл Python под названием start.py
- Добавьте файлы, которые нужно импортировать
- Запустите IPython или Jupyter Notebook, и необходимые библиотеки загрузятся автоматически!
Рассмотрим каждый шаг визуально. Размещение start.py :
import pandas as pd
import numpy as np
# Pandas options
pd.options.display.max_columns = 30
pd.options.display.max_rows = 20
from IPython import get_ipython
ipython = get_ipython()
# If in ipython, load autoreload extension
if 'ipython' in globals():
print('\nWelcome to IPython!')
ipython.magic('load_ext autoreload')
ipython.magic('autoreload 2')
# Display all cell outputs in notebook
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = 'all'
# Visualization
import plotly.plotly as py
import plotly.graph_objs as go
from plotly.offline import iplot, init_notebook_mode
init_notebook_mode(connected=True)
import cufflinks as cf
cf.go_offline(connected=True)
cf.set_config_file(theme='pearl')
print('Your favorite libraries have been loaded.')
При запуске сессии IPython появится следующее:
Проверить, загружены ли библиотеки, можно в globals() :
globals()['pd']globals()['np']
Теперь можно использовать интерактивную сессию без набора команд для загрузки этих библиотек! Этот способ также работает в Jupyter Notebook.
Примечания
- Файл может иметь любое название ( start.py легче запомнить), а startup/ может содержать несколько файлов. При запуске IPython они выполняются в лексикографическом порядке.
- При использовании этого способа с Jupyter Notebook ячейка с импортированными файлами отсутствует, поэтому при совместном использовании записной книжки скопируйте содержимое start.py в первую ячейку. Таким образом, другие пользователи могут увидеть, какие библиотеки вы используете.
- При работе на нескольких компьютерах нужно повторить эти действия. Обязательно используйте один и то же сценарий start.py , чтобы импортировать те же самые файлы!
- Также посмотрите официальную документацию
Этот способ избавит вас от лишних действий при начале работы с IPython и поможет создать более эффективную рабочую среду.
Подключение библиотек в Python
Вы используете устаревший браузер. Этот и другие сайты могут отображаться в нем неправильно.
Необходимо обновить браузер или попробовать использовать другой.
Алекса
Новичок
Пользователь
Апр 20, 2020 2 0 1
Всем добрый вечер!
Столкнулась с такой проблемой: не видит библиотек
Я пользуюсь Макбуком, скачала Anaconda3, Python 3.7 , пользуюсь юпитер ноутбук, но при этом юпитер не видит библиотек gensim, keras, tensorflow. Подскажите, что делать?
Vlad_SD
Активный пользователь
Пользователь
Апр 7, 2020 91 45 18
Добрый день, Алекса. как устанавливали библиотеки? какие-то ошибки python выводит при попытке import?
Вот хорошая статья по правильной установке библиотек
Установка Python и pip на Windows
Устанавливаем Python и менеджер пакетов Pip на Windows 10 с нуля. Какая разница между Python 32bit и Python 64bit.

python-scripts.com
если пользуететеь pycharm, то можно установить библиотеки через File —> Settings —> Project Settings