Как нормализовать данные и зачем это нужно
Нормализация данных является важным процессом в аналитике данных, который помогает привести различные масштабы и единицы измерения к единому виду. Это облегчает сравнение, анализ и обработку данных, особенно при использовании алгоритмов машинного обучения. В этой статье мы разберемся, что такое нормализация данных, как ее проводить и почему это важно.
Что такое нормализация данных
Нормализация данных – это процесс приведения разных масштабов и единиц измерения к единому виду. Это делается для того, чтобы упростить сравнение, анализ и обработку данных. В основе нормализации лежит идея о том, что данные должны быть представлены в виде, который облегчает их интерпретацию и использование.
Пример ненормализованных данных:
| Страна | Площадь, км² | Население, млн человек |
|———|—————|————————|
| Россия | 17,100,000 | 146 |
| США | 9,800,000 | 328 |
| Китай | 9,600,000 | 1400 |
Видно, что площадь и население измеряются в разных единицах, и сравнивать их напрямую сложно. Нормализация данных позволяет преобразовать эти значения в единый масштаб, упрощая анализ.
Методы нормализации данных
Существует несколько популярных методов нормализации данных, включая:
- Минимально-максимальная нормализация (min-max scaling)
- Z-преобразование (z-score normalization)
- Нормализация на основе среднего значения (mean normalization)
Минимально-максимальная нормализация
Минимально-максимальная нормализация – это простой метод, который преобразует данные таким образом, что все значения находятся в диапазоне от 0 до 1. Формула минимально-максимальной нормализации выглядит следующим образом:
x’ = (x — min(x)) / (max(x) — min(x))
где x – исходное значение, x’ – нормализованное значение, min(x) и max(x) – минимальное и максимальное значения в наборе данных соответственно.
Аналитик данных: новая работа через 5 месяцев
Получится, даже если у вас нет опыта в IT
Z-преобразование
Z-преобразование – это метод, который нормализует данные на основе среднего значения (μ) и стандартного отклонения (σ) набора данных. Формула z-преобразования выглядит следующим образом:
где x – исходное значение, x’ – нормализованное значение, μ – среднее значение набора данных, σ – стандартное отклонение набора данных.
Нормализация на основе среднего значения
Нормализация на основе среднего значения – это метод, который преобразует данные таким образом, что среднее значение набора данных становится равным 0. Формула нормализации на основе среднего значения выглядит следующим образом:
x’ = (x — mean(x)) / (max(x) — min(x))
где x – исходное значение, x’ – нормализованное значение, mean(x) – среднее значение набора данных, min(x) и max(x) – минимальное и максимальное значения в наборе данных соответственно.
Зачем нужна нормализация данных
Нормализация данных имеет ряд преимуществ:
- Упрощение сравнения данных: когда все данные представлены в едином масштабе, их легче сравнивать и анализировать.
- Ускорение обучения алгоритмов машинного обучения: многие алгоритмы обучаются быстрее, когда данные нормализованы.
- Повышение точности алгоритмов машинного обучения: нормализация данных может помочь алгоритмам сосредоточиться на важных аспектах данных, улучшая их точность и производительность.
Заключение
Нормализация данных является важным этапом в аналитике данных, который помогает привести различные масштабы и единицы измерения к единому виду. Это облегчает сравнение, анализ и обработку данных, а также улучшает работу алгоритмов машинного обучения. В этой статье мы рассмотрели основные методы нормализации данных и их преимущества.
Data Preparation: полет нормальный — что такое нормализация данных и зачем она нужна
Нормализация данных — это одна из операций преобразования признаков (Feature Transformation), которая выполняется при их генерации (Feature Engineering) на этапе подготовки данных (Data Preparation). В этой статье мы расскажем, почему необходимо нормализовать значения переменных перед тем, как запустить моделирование для интеллектуального анализа данных (Data Mining).
Что такое нормализация данных и чем она отличается от нормировки и нормирования
В случае машинного обучения (Machine Learning), нормализация — это процедура предобработки входной информации (обучающих, тестовых и валидационных выборок, а также реальных данных), при которой значения признаков во входном векторе приводятся к некоторому заданному диапазону, например, [0…1] или [-1…1] [1].
Следует отличать понятия нормализации, нормировки и нормирования.
Нормировка — это корректировка значений в соответствии с некоторыми функциями преобразования, с целью сделать их более удобными для сравнения. Например, разделив набор измерений о росте людей в дюймах на 2.54, мы получим значение роста в метрической системе.
Нормировка данных требуется, когда несовместимость единиц измерений переменных может отразиться на результатах и рекомендуется, когда итоговые отчеты могут быть улучшены, если выразить результаты в определенных понятных/совместимых единицах. Например, время реакции, записанное в миллисекундах, легче интерпретировать, чем число тактов процессора, в которых были получены данные эксперимента [2].
Нормирование — это процесс установления предельно допустимых или оптимальных нормативных значений в прикладных сферах деятельности, например, нормирование труда. Как правило, нормы разрабатываются по результатам исследовательских, проектных или научных работ, а также на основе экспертных оценок [3].
Нормализация, нормировка и нормирование — это разные понятия
Зачем нормализовать датасет для Data Mining и Machine Learning
Необходимость нормализации выборок данных обусловлена природой используемых алгоритмов и моделей Machine Learning. Исходные значения признаков могут изменяться в очень большом диапазоне и отличаться друг от друга на несколько порядков. Предположим, датасет содержит сведения о концентрации действующего вещества, измеряемой в десятых или сотых долях процентов, и показатели давления в сотнях тысяч атмосфер. Или, например, в одном входном векторе присутствует информация о возрасте и доходе клиента.
Будучи разными по физическому смыслу, данные сильно различаются между собой по абсолютным величинам [4]. Работа аналитических моделей машинного обучения (нейронных сетей, карт Кохонена и т.д.) с такими показателями окажется некорректной: дисбаланс между значениями признаков может вызвать неустойчивость работы модели, ухудшить результаты обучения и замедлить процесс моделирования. В частности, параметрические методы машинного обучения (нейронные сети, растущие деревья) обычно требуют симметричного и унимодального распределения данных. Популярный метод ближайших соседей, часто используемый в задачах классификации и иногда в регрессионном анализе, также чувствителен к диапазону изменений входных переменных [5].
После нормализации все числовые значения входных признаков будут приведены к одинаковой области их изменения — некоторому узкому диапазону. Это позволит свести их вместе в одной модели Machine Learning [4] и обеспечит корректную работу вычислительных алгоритмов [1].
Нормализованные данные в диапазоне [0..1]
Практическим приемам Feature Transformation посвящена наша следующая статья, где мы рассказываем, как именно выполняется нормализация данных: формулы, методы и средства. Все эти и другие вопросы Data Preparation рассматриваются в нашем новом курсе обучения для аналитиков Big Data: подготовка данных для Data Mining. Оставайтесь с нами!
Источники
Нормально делай – нормально будет: нормализация на практике — методы и средства Data Preparation

Мы уже рассказали, что такое нормализация данных и зачем она нужна при подготовке выборки (Data Preparation) к машинному обучению (Machine Learning) и интеллектуальному анализу данных (Data Mining). Сегодня поговорим о том, как выполняется нормализация данных: читайте в нашем материале о методах и средствах преобразования признаков (Feature Transmormation) на этапе их генерации (Feature Engineering).
Нормализация данных: методы и формулы
Существует множество способов нормализации значений признаков, чтобы масштабировать их к единому диапазону и использовать в различных моделях машинного обучения. В зависимости от используемой функции, их можно разделить на 2 большие группы: линейные и нелинейные. При нелинейной нормализации в расчетных соотношениях используются функции логистической сигмоиды или гиперболического тангенса. В линейной нормализации изменение переменных осуществляется пропорционально, по линейному закону.
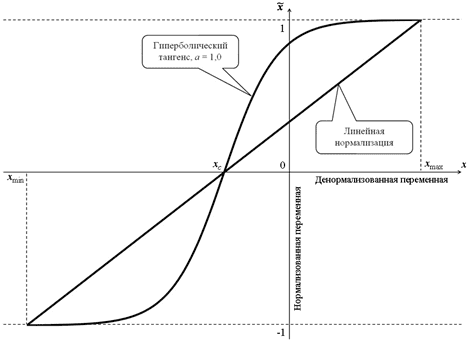
На практике наиболее распространены следующие методы нормализации признаков [1]:
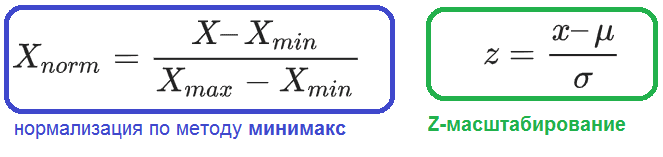
- Минимакс — линейное преобразование данных в диапазоне [0..1], где минимальное и максимальное масштабируемые значения соответствуют 0 и 1 соответственно;
- Z-масштабирование данных на основе среднего значения и стандартного отклонения: деление разницы между переменной и средним значением на стандартное отклонение;
- десятичное масштабирование путем удаления десятичного разделителя значения переменной.
На практике минимакс и Z-масштабирование имеют похожие области применимости и часто взаимозаменяемы. Однако, при вычислении расстояний между точками или векторами в большинстве случае используется Z-масштабирование. А минимакс полезен для визуализации, например, чтобы перенести признаки, кодирующие цвет пикселя, в диапазон [0..255] [2].
Как нормализовать данные для машинного обучения и Data Mining
Чтобы выполнить нормализацию данных, нужно точно знать пределы изменения значений признаков: минимальное и максимальное теоретически возможные значения. Этим показателям будут соответствовать границы интервала нормализации. Когда точно установить пределы изменения переменных невозможно, они задаются с учетом минимальных и максимальных значений в имеющейся выборке данных [3].
На практике data scientist нормализует данные с помощью уже готовых функций интегрированных сред для статистического анализа, например, IBM SPSS, SAS или специальных библиотек: Scikit-learn, Auto-sklearn, pandas и т.д. Кроме того, аналитик данных может написать собственный код на языке R или Python для почти любой операции Data Preparation [4].

Подробно о том, как нормализовать данные и другие аспекты Data Preparation в нашем новом образовательном курсе для аналитиков Big Data в Москве: подготовка данных для Data Mining. Присоединяйтесь!
Источники
- https://docs.microsoft.com/ru-ru/azure/machine-learning/team-data-science-process/prepare-data
- https://habr.com/ru/company/ods/blog/325422/
- https://neuronus.com/theory/nn/925-sposoby-normalizatsii-peremennykh.html
- https://bigdataschool.ru/bigdata/data-preparation-operations.html
Нормализация данных (Data normalization)
В машинном обучении нормализацией называют метод предобработки числовых признаков в обучающих наборах данных с целью приведения их к некоторой общей шкале без потери информации о различии диапазонов.
Иногда нормализацию данных называют стандартизацией, однако это неверно. Стандартизация это более широкое понятие и подразумевает предобработку с целью приведению данных к единому формату и представлению, наиболее удобному для использования определённого вида обработки. В отличии от нормализации, стандартизация может применяться и к категориальным данным.
Необходимость нормализации вызвана тем, что разные признаки обучающего набора данных могут быть представлены в разных масштабах и изменяться в разных диапазонах. Например, возраст, который изменяется от 0 до 100, и доход, изменяющийся от нескольких тысяч до нескольких миллионов. То есть диапазоны изменения признаков «Возраст» и «Доход» различаются в тысячи раз.
В этом случае возникает нарушение баланса между влиянием входных переменных, представленных в разных масштабах, на выходную переменную. Т.е. это влияние обусловлено не реальной зависимостью, а изменением масштаба. В результате, обучаемая модель может выявить некорректные зависимости.
Существует несколько основных методов нормализации.
Десятичное масштабирование (decimal scaling)
В данном методе нормализация производится путём перемещения десятичной точки на число разрядов, соответствующее порядку числа: x ′ i = x i / 10 n , где n — число разрядов в наибольшем наблюдаемом значении. Например, пусть имеется набор значений: -10, 201, 301, -401, 501, 601, 701. Поскольку n=3, то получим x ′ i = x i / 10 3 . Иными словами, каждое наблюдаемое значение делим на 1000 и получаем: -0.01, 0.201, 0.301, -0.401, 0.501, 0.601, 0.701.
Минимаксная нормализация
Несложно увидеть недостаток предыдущего метода: результирующие значения всегда будут занимать не весь диапазон [0,1], а только его часть, в зависимости от наибольшего и наименьшего наблюдаемых значений. Если исходный диапазон мал (скажем, 400 — 500), то получим, что в результате десятичного масштабирование нормализованные значения будут лежать в диапазоне [0.4,0.5], т.е. его изменчивость окажется очень низкой, что плохо сказывается на качестве построенной модели.
Решить проблему можно путём применения минимаксной нормализации, которая реализуется по формуле:
X ′ = X − X m i n X m a x − X m i n .
Эту формулу можно обобщить на привидение исходного набора значений к произвольному диапазону [ a , b ] :
X ′ = a + X − X m i n X m a x − X m i n ( b − a ) .
Наиболее часто используется приведение к диапазонам [0,1] и [-1,1]
Нормализация средним (Z-нормализация)
Недостаткам минимаксной нормализации является наличие аномальных значений данных, которые «растягивают» диапазон, что приводит к тому, что нормализованные значения опять же концентрируются в некотором узком диапазоне вблизи нуля. Чтобы избежать этого, следует определять диапазон не с помощью максимальных и минимальных значений, а с помощью «типичных» — среднего и дисперсии:
x ′ i = ( x i − ¯ ¯¯¯ ¯ X ) / σ x .
Величины, полученные по данной формуле, в статистике называют Z-оценками. Их Абсолютное значение представляет собой оценку (в единицах стандартного отклонения) расстояния между x и его средним значением ¯ ¯¯¯ ¯ X в общей совокупности. Если z меньше нуля, то x ниже средней, а если z больше нуля, то x выше средней.
Отношение
В этом методе каждое значение исходных данных делиться на некоторое, заданное пользователем число, или на значение статистического показателя, вычисленного по набору данных, например, среднее, стандартное отклонение, дисперсию, вариационный размах и др.